Hex Review & Go/No-go
Written by
|
Posted on
How to use:
Sign in with google
Create a project
Make sure the data source is pointed at "granted snowflake" (see screenshot)
Open the ai editor (in the bottom right corner) and a side panel chat should pop up. toggle on the "alpha features" and also make sure the chat's data source is pointed at granted snowflake as well (see screenshot).
Start asking questions! it's good for things like: "what kind of documents do we keep in our database?" or "how many users have connected their insurance via a weblink? or "give me a table of our super users - that is, all of our users who have created at least 20 cases in our system." but I'm also curious what you want to try and whether or not it's good at those things too!
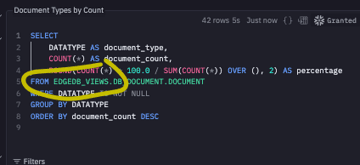
The SQL should be generated for you! Even if you don't use SQL, if you could make sure that the AI is accessing the "edgedb_views" table I would appreciate it! attached an image of where to see that. if this said "edgedb" or "rudderstack" please let me know!
Working table:
add any experiment you tried and what you think! make as many rows as experiments you tried.
Name | What did you try? | What did you like | What did you not like? |
|---|---|---|---|
Jimmy | Cost per case deep dive | It very quickly generated accurate SQL, and made proper guesses as to what table to use. | it didn’t always the semantics right. It couldn’t figure out that a “test case” had to do with the case management type, for instance. “Link” as our name for insurance connections is very hard for the model. |
Jimmy | Making a dashboard | I like the toggle on/off from a cell to the app builder | I found the charts to missing customizations. For instance, we wanted to show two values for a given column and there was no way to label a bar chart with anything besides the value of the bar. |
Miguel | Drill down into Extract Data | Once I got my target data synced in Snowflake, was able to easily combine SQL + Python to drill onto JSON structures. | Some of the Python generated was ok, used an external AI (Grok) to help and got it going. A bit messy with structuring the notebook for sharing, but I guess the App view makes that possible. |
Miguel | Endpoint Summary | Quick ask to look into some data, knew I would need some joins, and Hex took care of this pretty well within 10 minutes. | Had to keep poking to handle duplicates in the data, but we eventually got there. |
Natalie | Getting a list of our most 30 active users | It got me the answer pretty quickly without me having to open metabase and do weird joins which I appreciate | It did give some weird outputs at first that “the top message sending users have created 0 cases”, but corrected after I changed the prompt a bit |
Natalie | From the top users, asked questions about their trends in questions asked | It gave me a human readable analysis | The analysis was pretty high level — I probably could have gone deeper with prompting to get more specific and thought more about categorization by keywords or something. |
Natalie | EOB Findings research | It was so much easier to paint a picture of EOB Findings efficacy at driving case creation, and compare that to the overall landscape of billing case creation / resolution | Some of our EOB Findings info is only stored as event data so it’s in Amplitude and I couldn’t get it in Hex — but that’s not Hex’s fault (and I think would just push us more to make sure everything is available in Hex). |
Niki | give me a table of users who have opened at least 5 cases and list out who their insurer carrier is | this is the response i got: “I can see there are users with 5+ cases (the top user has 84 cases!), but the query returned no results because we're not finding matching insurance carrier information. Let me check what insurance data is actually available and update the query.” perhaps it’s because i’m not using the right language | |
Niki | how many users have connected Aetna insurance? | this answer must surely be wrong: 1 user has connected Aetna insurance to their account.The query shows all insurance carriers that users have connected, and Aetna has 1 user connected, along with Cigna Corporation (1 user) and Tufts Health Plan (1 user). | |
Niki | exploration of mental health case types and users | this one performed much better! gave me a great overview and data to work with | |
Vitaliy | Summarize RPA executions by P0/P1 for a given week | It figured out the right tables/joins pretty quickly | Seems to have tendency to keep adding pages to notebook instead of revisting existing ones. Used python to summarize data instead of doing it in sql |
Sanat | Map upstream keywords to specific user actions | Very fast in getting from 0→100 in terms of queries. | Some errors at times and I still end up reading through the code to verify it’s pulling stuff correctly |
Sanat | HIPAA completion rates | Very fast, also formatted my existing SQL and found bugs. | Joined on the wrong DB at first |
Summarization table: Add one row per person
Name | General value of the tool (F-A+) | How often would you use it? | Would you replace Metabase with it? | Other thoughts? |
|---|---|---|---|---|
Jimmy | A- | Weekly | Yes (but slowly) | |
Miguel | A | Daily/Weekly | Yes (and quickly) | Messing with SQL in Metabase is painful; have to use an external AI to iterate and need to add a bunch of context. With Hex its all integrated, and can use code if I wanted to. |
Natalie | A | Daily / multi-weekly | Yes (slowly) | Would need to migrate all of the charts over which doesn’t feel like a small undertaking? Could be wrong. I also haven’t explored the charting feature very extensively, so not sure about the robustness of visual reports. I have found it exceptionally good though for doing quick research which is super powerful when doing product work. |
Vitaliy | A | Weekly | Likely | Same thoughts as Miguel. |
Sanat | A- | Daily | Yes (very slowly) | Overall, definitely approve of it, very useful for getting data insights. I do think though it makes it faster for semi-data savvy folks to get data faster vs getting data for people with low data literacy (more on that bellow) We would need to clean up our database metadata a bit so that we can guide the LLM better. For example, insurance link has multiple data sources (flexpa db, insurance link db, etc.) and it can get confused on what db to use. Biggest worry is that this tool is designed to help people with lower technical knowledge in sql + python to get data insights but there could be cases where we’re getting #s that aren’t correct and non-technical folks use them as sources of truth. An example for me was looking into HIPAA data, I got a result back for HIPAA completion % but upon looking into the SQL, it was making an assumption on a db that was incorrect (someone with less data literacy could potentially not make that deduction and use the wrong value) |
Scratch notes:
Tips & How-To Guides